



20 Ene 22
Ransomware. Significado y cómo identificarlo
Actualmente se habla mucho del ransomware. En este artículo queremos contarte qué es y cómo identificarlo. Su nombre deriva de […]

Cuando comencé en Transparent Edge, uno de mis primeros encargos fue implementar un sistema de envío de logs en tiempo real para nuestros clientes. Tenía que ser un sistema capaz de distribuir miles de millones de logs al día o registros al día, con una latencia baja y un alto rendimiento, por lo que en el equipo coincidimos en que el eje central tenía que ser Apache Kafka.
Lo mejor de trabajar en una compañía que ofrece un producto vivo y en constante desarrollo es verlo crecer en primera persona, muchas veces siendo cómplice de ello. Si a esto añadimos un equipo que te hace partícipe en todas sus fases, consigues una visión global que te permite no solo aprender multitud de nuevas tecnologías, sino saber cómo y dónde aplicarlas.
Si algo caracteriza al mundo de la tecnología y más específicamente al del software, es que se encuentra en constante evolución. Cada día aparece una nueva aplicación, un nuevo framework que promete ser mejor que los existentes e, incluso, un nuevo lenguaje de programación.
Por ello es importantísimo saber acudir a la documentación en todas sus formas, ya sea en su página web, en el README de un repositorio Git, en el manpage… El caso de Kafka no era distinto.
Pronto empezaron a surgir preguntas: ¿qué requisitos tiene?, ¿cuántos nodos hacen falta para conseguir una alta disponibilidad?, ¿cómo auténtico y autorizo a los usuarios?
Gracias a la documentación pude resolverlas y en no demasiado tiempo ya disponíamos de un clúster operativo, preparado para autenticar y autorizar no solo a nuestros clientes, sino también a los futuros “productores” que ingestarían de logs en tiempo real desde los distintos servidores de la CDN.
La siguiente fase era conseguir implementar un sistema ingestara los logs que se generan en toda la plataforma de la forma más ligera posible. Y esto presentaba algunas dificultades.
Nuestra plataforma cuenta con varios tipos de servidores según su propósito y no todos ejecutan el mismo software ni vuelcan el mismo tipo de log. No es lo mismo un servidor de nuestra plataforma de media, optimizado para transmisión en vivo, que uno de nuestra plataforma de delivery, optimizado en web caching y baja latencia.
El sistema tenía que ser lo suficientemente flexible como para adaptarse con facilidad a los posibles nuevos tipos de servidores y/o formatos de log y a su vez muy ligero, ya que se ejecutaría en el edge, y ahí cada ciclo de CPU cuenta.
En cuanto al rendimiento, por suerte existe la librería librdkafka, que implementa el protocolo de Kafka en C, y confluent-kafka-python, que hace uso de dicha librería para conseguir un rendimiento óptimo aun usando Python, un lenguaje muy flexible.
De nuevo, había que recurrir a la documentación, esta vez de librdkafka y confluent-kafka-python, y poco a poco fue tomando forma nuestro producer, nombre que hace honor al concepto de producer y consumer en Kafka.
Para recuperar los logs, el proceso detecta en qué tipo de plataforma se está ejecutando y utiliza el método adecuado. Por ejemplo, en nuestra plataforma de media hace uso de named pipes y en nuestra plataforma de delivery ejecuta directamente una utilidad (un logger), que vuelca los logs de Varnish directamente desde memoria.
Todos los logs de nuestra plataforma cuentan con un campo que representa el identificador de cliente. El producer, cuando recibe uno de estos logs, debe decidir a qué cliente pertenece para poder enviarlo a la cola correcta (que en Kafka se llama topic).
Este proceso de determinar el cliente para cada log se ejecuta, en tiempo real, sobre todos y cada uno de los millones de logs que genera nuestra plataforma a diario. Y estamos utilizando Python, un lenguaje interpretado y de alto nivel que no ofrece un alto rendimiento (aunque sí compila a bytecode ciertas partes).
Para evitar que esto se convierta en un cuello de botella y que utilice la menor cantidad de CPU posible, lo que hacemos es anteponer el identificador de cliente al principio de los logs que recibe el producer y obtenerlo de esta forma tan simple:
for data in self._varnishncsa.stdout:
clientid, logstring = data.split(" ", 1)
self._produce_to_kafka(clientid, logstring)
Es decir, se realiza un split una sola vez sobre el log y ya tenemos por separado el identificador de cliente y el log en sí.
El resto del trabajo queda delegado en la librería libro Kafka, que es la encargada de agrupar, comprimir y enviar los logs a Kafka. Todo esto unido a un pequeño tuning en la configuración…
"compression.codec": "gzip", "retry.backoff.ms": 3000, "queue.buffering.max.messages": 250000, "queue.buffering.max.ms": 1000, # alias of linger.ms "batch.num.messages": 10000, "topic.metadata.refresh.interval.ms": 150000, "socket.timeout.ms": 45000, "socket.keepalive.enable": True,
…es lo que permite al final ingestar los logs al clúster de Kafka sin robar preciados ciclos de CPU a los nodos del edge.
Por último, solo faltaba pegar todos estos componentes y automatizar el proceso de alta de todo nuevo cliente que quiera consumir sus logs en tiempo real.
Para ello, implementamos en nuestro panel una nueva sección dentro del servicio de entrega de logs. Ya teníamos el servicio de entrega periódico habitual y el servicio en streaming:
Cuando uno de nuestros clientes se suscribe (de forma totalmente transparente y gratuita) al servicio de streaming de logs, se envía una petición a nuestra API que lo incluye en la lista de clientes con el servicio activo.
Esto desencadena una serie de procesos:
Dichos procesos no demoran más allá de 5 minutos. Una vez activo el servicio, el panel muestra lo siguiente a nuestro cliente:
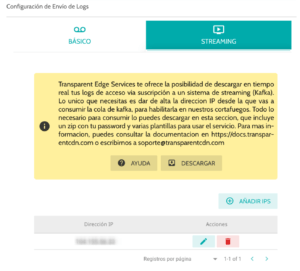
Aquí puede descargar un archivo zip que se genera automáticamente e incluye todo lo necesario para poder empezar a consumir sus logs en tiempo real. Este contiene ejemplos ya configurados para distintos tipos de aplicaciones compatibles con Kafka como Filebeat, Logstash o directamente un script personalizado en Python, así como los certificados necesarios para poder autenticarse.
Así ya teníamos todo listo y Transparent Edge disponía de su servicio de envío de logs en tiempo real.
Manu Sánchez Pinar es Linux SysAdmin – DevOps en Transparent Edge.
Si en vez de al T-1000 hubieran puesto a Manu a perseguir a Terminator, la película hubiera durado cinco minutos y le habría instalado NixOS. Analítico, metódico y entusiasta del software libre, administra y hace crecer sin descanso la infraestructura y servicios de Transparent Edge, manteniéndola limpia como una patena.
Compartir:

