


11 Dic 25
La cabecera Vary: sacando partido a la negociación de contenido para hacer (un poco) de todo
Sacando partido a la negociación de contenido para hacer (un poco) de todo con la cabecera Vary.

Diego Suarez
26 Aug 25

– ¿Tienes entradas libres? ¿Sí? ¡Dámelas! ¡Dámelas! ¡Dámelas! ¡Dámelas!
Esta es la historia de un sitio web de venta de entradas de un complejo monumental cuya web se caía prácticamente a diario porque recibía indiscriminadamente ataques en un rango horario entre las 23:00 h y las 2:00 h de la mañana. Y puede ser también la historia de cualquier otro sitio de venta de bienes escasos que conozcas.
Te contaremos cómo Transparent Edge intervino para que recuperen el control de sus operaciones previniendo pérdidas económicas y de reputación.
Los bots automatizados compraban los tickets para luego venderlos en agencias de viajes que hacían su agosto inflando los precios en reventa y perjudicando tanto a usuarios como a la empresa que vendía sus entradas a un precio justo.
Incansables, recorrían todo el sitio buscando la URL donde poder comprar y por el camino generaban un exceso de tráfico desmedido, visitando incluso las secciones menos vistas, esas que estaban allí por SEO o por requisito legal.
La alocada búsqueda de entradas disponibles terminaba interrumpiendo la disponibilidad de la web, perjudicando a los usuarios genuinos y al negocio.
En las siguientes infografía se muestra cómo la cantidad de peticiones recibidas (requests/segundo) comprometían la disponibilidad del sitio web, que superando las 30 rps se caía.
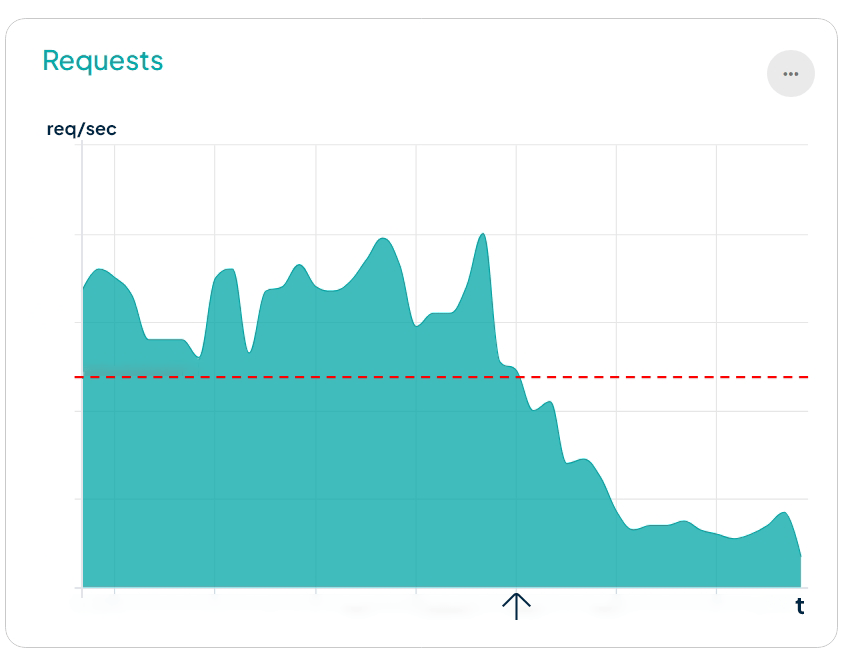
Otro parámetro que comprometía la accesibilidad al sitio era el tiempo de respuesta. Cuando se reciben exceso de peticiones, los tiempos de respuesta aumentaban por encima de 2s y el servidor devolvía códigos HTTP 408 de timeout.
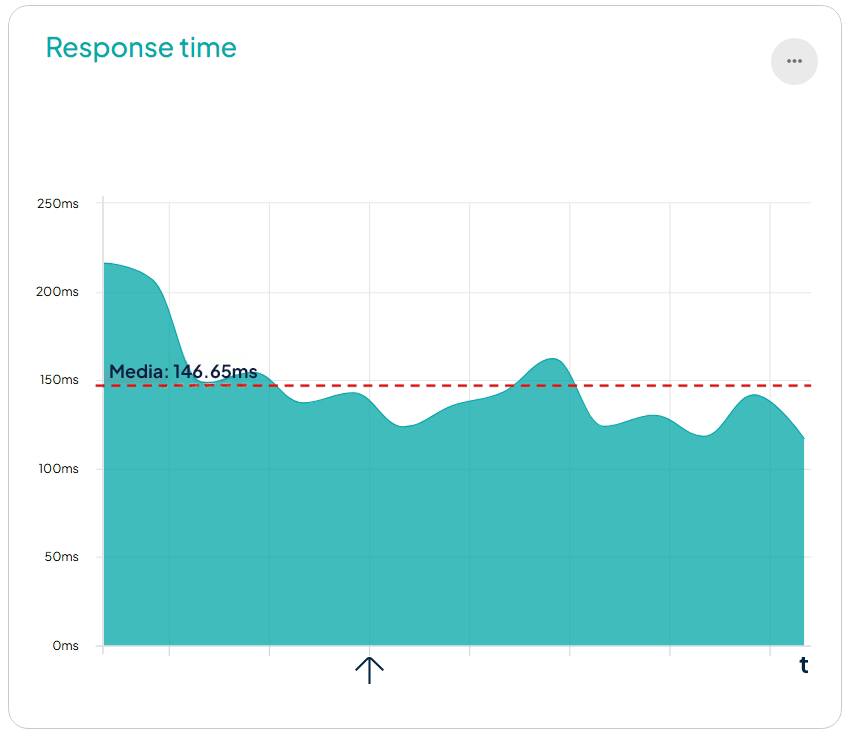
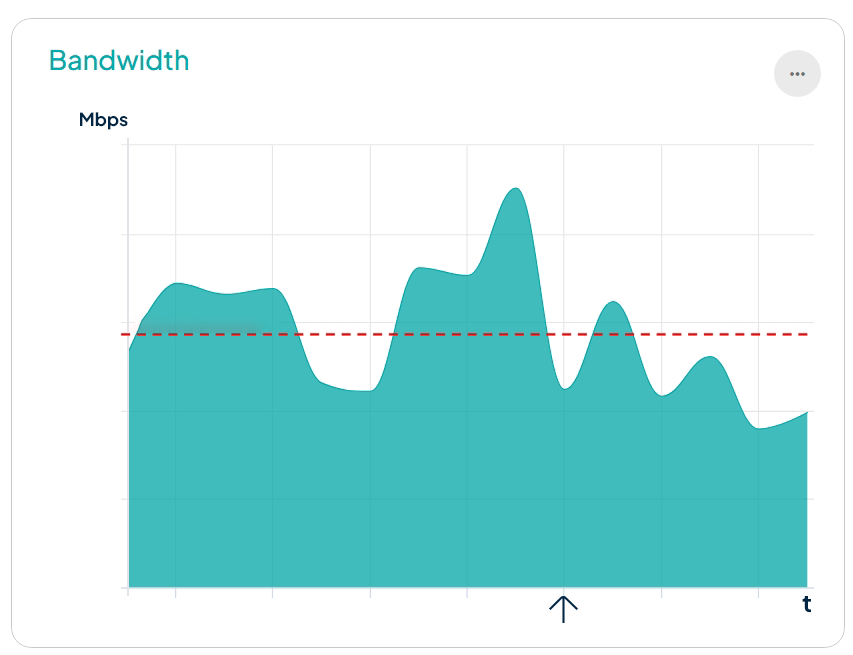
La combinación perfecta para que Transparent Edge entrase en acción: un sitio que se cae con frecuencia, unos costes de infraestructura elevados por el exceso de tráfico y un claro incumplimiento de las reglas de fair use.
El OWASP Automated Threat Handbook for Web Applications define el scalping (OAT-005) como una amenaza diseñada para «obtener bienes/servicios exclusivos y/o de disponibilidad limitada mediante métodos injustos».
Tamaña tropelía requería una intervención, y así es como lo hicimos.
La primera medida fue colocar la CDN por delante del origen. De esta manera los usuarios se conectan a la plataforma y no directamente al sitio web. Esta medida no requiere cambios de infraestructura y es un proceso rápido sin interrupción en el servicio ni pérdida de información. A partir de ese momento solo las peticiones de los nodos accedían al servidor y su tráfico disminuyó drásticamente más del 50%.
Lo siguiente fue activar el Anti-DDoS para capas 3, 4 y 7 y establecer un rate-limit. Como aún no se sabía de dónde provenía ese tráfico que tumbaba el sitio, se activó un umbral de peticiones máximas, para que todo lo que excediera el umbral fuera bloqueado.
Un código de estado HTTP 429 indica que una IP ha enviado demasiadas solicitudes a un servidor en un corto periodo de tiempo. Puede provenir de IP que hacen peticiones abusivas, o excesivas en muy poco tiempo. En respuesta se activa el Under Attack Mode que bloquea el acceso a esas requests e implementa una limitación de velocidad para mitigar el impacto del ataque, evitando que este tráfico bruto excesivo sature los recursos y haga caer al servidor.
Desde algunas IP recibían visitas frecuentes e indiscriminadas, por lo tanto el siguiente paso fue colocar un umbral bajo de scoring para que las IP de baja reputación o provenientes de un ASN con alto scoring puedan ser bloqueadas.
Si desde una IP se reciben más de cierta cantidad de requests por segundo, se la puede penalizar por una franja de tiempo, por ejemplo 12 h, y además se le suma puntaje (especialmente si reincide).
Este parámetro es personalizado para el tipo de sitio y casuística. En este caso y por la frecuencia y volumen de scalping que recibían se optó por poner parámetros restrictivos, que luego se podrían modificar y volver más permisivos.
Con mecanismos automatizados de navegación los bots procuran hacerse con las entradas libres. Utilizan motores como Selenium o similares que son un conjunto de herramientas de software de código abierto diseñadas para automatizar los navegadores web. Así pueden bombardear el sitio web con peticiones en busca de tickets.
Una vez encontrada la localización de la URL de venta de entradas, continuaban el proceso de compra como si fueran un usuario humano convencional, con la diferencia que completan el proceso completo en una fracción del tiempo del que le toma a una persona real.
Los bots no se llevan solamente algunas entradas, sino que son capaces de recoger todo el inventario porque los compradores comunes y corrientes nunca pueden ganarles en velocidad. A corto plazo, esto genera quejas de los usuarios y perjudica la confianza en el sitio web a medio plazo.
Los operadores de bots scalpers más sofisticados ahorran milisegundos adicionales en el proceso de adquisición balanceando y distribuyendo sus servidores geográficamente para explotar la latencia de las señales de datos.
Y mientras tanto, los bots consumen un ancho de banda significativo y perjudican la velocidad y rendimiento del sitio web. Todo ello redunda en un aumento de los costes de infraestructura y la necesidad de tener al equipo de TI apagando incendios continuamente.
Colocando desafíos JS, conseguimos que el tráfico automatizado no sea capaz de acceder al site, restringiendo de manera efectiva la venta de entradas a usuarios humanos, que son los únicos que pueden acceder al proceso de compra.
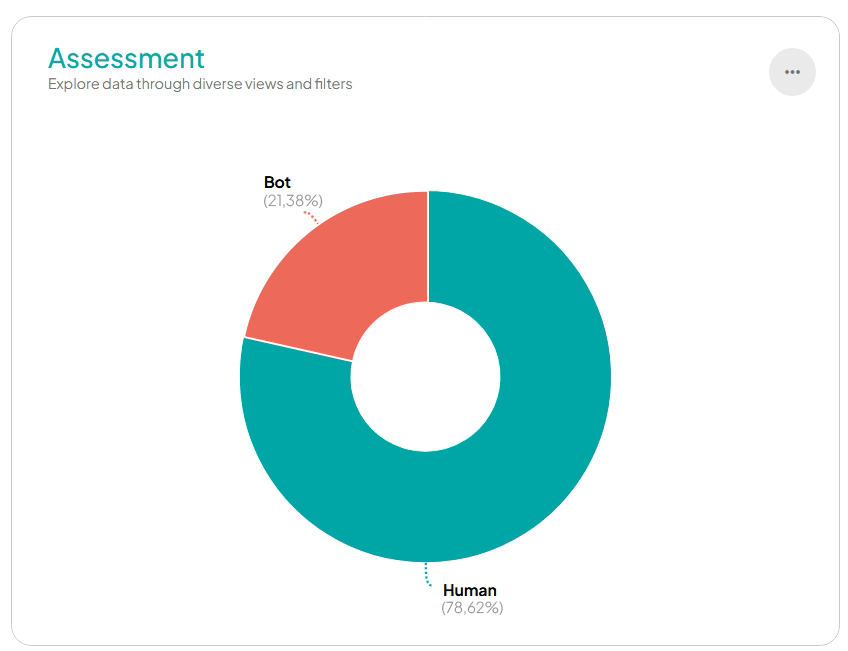
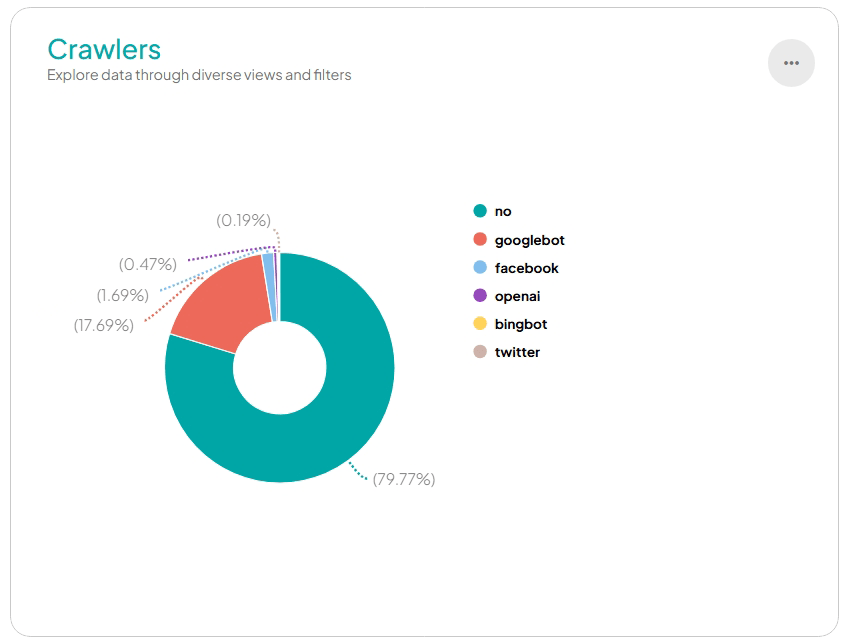
Otra posible capa de protección ante tráfico automatizado está relacionada con la ubicación geográfica de las peticiones. El equipo de Transparent Edge definió que en caso de IP de ciertas regiones, automáticamente se presentase un desafío JavaScript. Esta prueba es imperceptible para el usuario legítimo y sin embargo una traba para el bot.
Aquellos bots suficientemente desarrollados como para actuar como navegador o tener comportamientos similares a los humanos pueden eventualmente pasar el Anti-DDoS, por eso se necesitan capas de protección adicionales. En este caso se definió un umbral a partir del cual la navegación del usuario se considera una anomalía y se acciona una reacción automatizada. Por ejemplo, si pasa las 100 peticiones por minuto, ya no se trata de una persona comprando sus entradas, sino que es un crawler y el sistema reacciona bloqueando su ingreso por 24 h.
| Tipo de anomalía | Reacción |
|---|---|
| Por IP request | Bloquea la IP por 12 h |
| Por traffic request | Activa UAM por 4 h |
| Por ancho de banda | Activa UAM por 4 h |
| Increase in country request | Activa UAM por 4 h |
| IP crawler | Bloqueo IP por 24 h |
Un WAF puede funcionar en modo detección o en modo activo. Y en diferentes momentos podemos necesitar uno u otro modo de operar.
Como algunos bots mejor programados pueden ejecutar sus comandos más despacio para simular el comportamiento de los humanos, los técnicos de Transparent Edge optaron por agregar otras capas de protección y generar expresiones regulares que validan los parámetros que se pasan a las URL de compra. Así lograron que las variables que se pasan al backend respondan a la estructura y tipología que deben tener y descartamos todas las pruebas aleatorias que puedan hacer los bots rechazando sus intentos de acceso.
Es natural que ciertas IP hagan compras frecuentes, así que esas IP de confianza las agregamos a una whitelist y le concedemos permisos de accesos menos restrictivos. No significa que tengan vía libre, sino que sus límites para ser catalogados como anomalía son más laxos.
Una vez establecido el modelo de controles de observabilidad y defensa básicos, el equipo pudo pasar a un ajuste fino y granular utilizando la versatilidad que ofrece el lenguaje VCL (Varnish Configuration Language).
Ejemplo de esto es hacer un deny_request a un script Python o Go o capar a quienes tienen cabeceras de NoName(057).
CÓDIGO DE EJEMPLO:
# Restricción de acceso a clientes de ‘Go’ o ‘Python’
if (req.http.User-Agent ~ "(?i)(go-http-client/|python-requests)") {
call deny_request;
}
# Restricción de acceso a NoName(057) teniendo en consideración el patrón conocido para la cabecera ‘Accept’
if (req.http.Accept == "text/html,application/xhtml+xml,application/xml,") {
call deny_request;
}
El tráfico del sitio web disminuyó en un 60 %. Su sitio lleva más de un año totalmente operativo, cero caídas. Han dejado de recibir quejas telefónicas y en redes sociales por imposibilidad de comprar entradas. Los clientes legítimos pueden comprar sus entradas sin problema. Y envían una caja de Manolitos a nuestro equipo técnico cada mes, porque su equipo IT está feliz.
¿Quieres un equipo de IT tranquilo y dedicado a proyectos de desarrollo, unos clientes humanos satisfechos y una web que funcione 24/7 rápida y segura? ¡Llámanos! Te enseñaremos a desplegar la mejor configuración de protección para tus sitios web y API. Con capas transversales de seguridad, detección y mitigación. Te acompañamos con la experiencia de nuestros ingenieros al implementar optimizaciones personalizadas a tu necesidad.
Y si tu sitio o aplicación web no es de venta de entradas, pero sufre algún otro tipo de ataque, también puedes llamarnos. Comprueba cómo pasas a controlar tu entorno y disfrutar de tus tareas.
#secureYourSite
Compartir:

